Vincent Bernat: Non-interactive SSH password authentication
SSH offers several forms of authentication, such as passwords and
public keys. The latter are considered more secure. However, password
authentication remains prevalent, particularly with network equipment.1
A classic solution to avoid typing a password for each connection is
sshpass, or its more correct variant passh. Here is a wrapper for Zsh,
getting the password from pass, a simple password manager:2
This approach is a bit brittle as it requires to parse the output of the
If the password is incorrect, we can display a prompt on the second
tentative:
A possible improvement is to use a different password entry depending on the
remote host:3
It is also possible to make
For the complete code, have a look at my zshrc. As an alternative, you can
put the
pssh() passh -p <(pass show network/ssh/password head -1) ssh "$@" compdef pssh=ssh
ssh
command to look for a password prompt. Moreover, if no password is required, the
password manager is still invoked. Since OpenSSH 8.4, we can use
SSH_ASKPASS and SSH_ASKPASS_REQUIRE instead:
ssh() set -o localoptions -o localtraps local passname=network/ssh/password local helper=$(mktemp) trap "command rm -f $helper" EXIT INT > $helper <<EOF #!$SHELL pass show $passname head -1 EOF chmod u+x $helper SSH_ASKPASS=$helper SSH_ASKPASS_REQUIRE=force command ssh "$@"
ssh() set -o localoptions -o localtraps local passname=network/ssh/password local helper=$(mktemp) trap "command rm -f $helper" EXIT INT > $helper <<EOF #!$SHELL if [ -k $helper ]; then oldtty=\$(stty -g) trap 'stty \$oldtty < /dev/tty 2> /dev/null' EXIT INT TERM HUP stty -echo print "\rpassword: " read password printf "\n" > /dev/tty < /dev/tty printf "%s" "\$password" else pass show $passname head -1 chmod +t $helper fi EOF chmod u+x $helper SSH_ASKPASS=$helper SSH_ASKPASS_REQUIRE=force command ssh "$@"
ssh() # Grab login information local -A details details=($ =$ (M)$ :-"$ (@f)$(command ssh -G "$@" 2>/dev/null) " :#(host hostname user) * ) local remote=$ details[host]:-details[hostname] local login=$ details[user] @$ remote # Get password name local passname case "$login" in admin@*.example.net) passname=company1/ssh/admin ;; bernat@*.example.net) passname=company1/ssh/bernat ;; backup@*.example.net) passname=company1/ssh/backup ;; esac # No password name? Just use regular SSH [[ -z $passname ]] && command ssh "$@" return $? # Invoke SSH with the helper for SSH_ASKPASS # [ ]
scp invoke our custom ssh function:
scp() set -o localoptions -o localtraps local helper=$(mktemp) trap "command rm -f $helper" EXIT INT > $helper <<EOF #!$SHELL source $ (%):-%x ssh "\$@" EOF command scp -S $helper "$@"
ssh() function body into its own script file and replace command ssh
with /usr/bin/ssh to avoid an unwanted recursive call. In this case, the
scp() function is not needed anymore.
- First, some vendors make it difficult to associate an SSH key with a user. Then, many vendors do not support certificate-based authentication, making it difficult to scale. Finally, interactions between public-key authentication and finer-grained authorization methods like TACACS+ and Radius are still uncharted territory.
- The clear-text password never appears on the command line, in the environment, or on the disk, making it difficult for a third party without elevated privileges to capture it. On Linux, Zsh provides the password through a file descriptor.
-
To decipher the fourth line, you may get help from
print -land the zshexpn(1) manual page.detailsis an associative array defined from an array alternating keys and values.







 My stall. Photo credits: Tejaswini.
My stall. Photo credits: Tejaswini.
 Snacks and tea at the front desk. CC-BY-SA 4.0 by Ravi Dwivedi.
Snacks and tea at the front desk. CC-BY-SA 4.0 by Ravi Dwivedi.
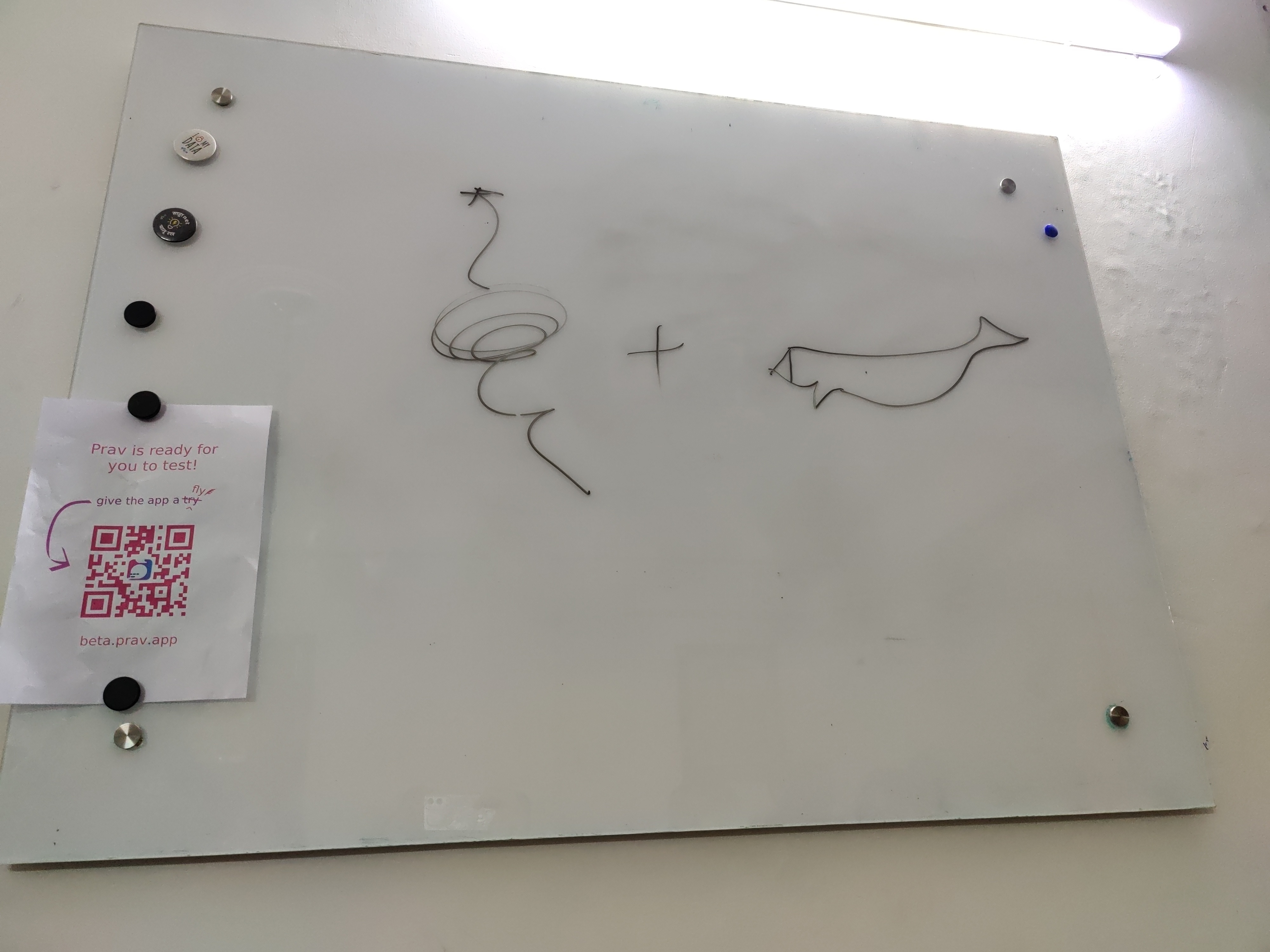 Pictionary drawing nowhere close to the intended word Wireguard :), which was guessed. Photo by Ravi Dwivedi, CC-BY-SA 4.0.
Pictionary drawing nowhere close to the intended word Wireguard :), which was guessed. Photo by Ravi Dwivedi, CC-BY-SA 4.0.
 Group photo. Photo credits: Tejaswini.
Group photo. Photo credits: Tejaswini.
 Tasty cake. CC-BY-SA 4.0 by Ravi Dwivedi.
Tasty cake. CC-BY-SA 4.0 by Ravi Dwivedi.
 Merchandise by sflc.in. CC-BY-SA 4.0 by Ravi Dwivedi.
Merchandise by sflc.in. CC-BY-SA 4.0 by Ravi Dwivedi.
 For documentation, please have a look at:
For documentation, please have a look at:
 This post describes how to handle files that are used as assets by jobs and pipelines defined on a common gitlab-ci
repository when we include those definitions from a different project.
This post describes how to handle files that are used as assets by jobs and pipelines defined on a common gitlab-ci
repository when we include those definitions from a different project.
 A minor maintenance release of the
A minor maintenance release of the 
 . Internet shutdowns impact women
. Internet shutdowns impact women 
 After Debian 12 aka bookworm was released yesterday, I've also created
new FAI ISO images using Debian 12.
The defaut ISO (large) uses FAI 6.0.3, kernel 6.1 and can install the
XFCE and GNOME desktop without internet connection, since all needed
packages are included into the ISO. Additional you can install Ubuntu
22.04 or Rocky Linux 9 with this FAI ISO. During these installations,
the packages will be downloade via network.
There's also the variant FAI ISO UBUNTU, which includes all Ubuntu
packages needed for a Ubuntu server or Ubuntu desktop installation.
If you need a small image, you can take the FAI ISO small, which only
includes the packages for a XFCE desktop without LibreOffice. This ISO
is only 880MB in size.
Currently I'm working on a new feature, so FAI can create Live
images, that are bootable. It's like the tool live-build which Debian
uses for their official Debian Live images.
A first verison of the ISO using the XFCE desktop can be downloaded
from
After Debian 12 aka bookworm was released yesterday, I've also created
new FAI ISO images using Debian 12.
The defaut ISO (large) uses FAI 6.0.3, kernel 6.1 and can install the
XFCE and GNOME desktop without internet connection, since all needed
packages are included into the ISO. Additional you can install Ubuntu
22.04 or Rocky Linux 9 with this FAI ISO. During these installations,
the packages will be downloade via network.
There's also the variant FAI ISO UBUNTU, which includes all Ubuntu
packages needed for a Ubuntu server or Ubuntu desktop installation.
If you need a small image, you can take the FAI ISO small, which only
includes the packages for a XFCE desktop without LibreOffice. This ISO
is only 880MB in size.
Currently I'm working on a new feature, so FAI can create Live
images, that are bootable. It's like the tool live-build which Debian
uses for their official Debian Live images.
A first verison of the ISO using the XFCE desktop can be downloaded
from
 I m calling time on DNSSEC. Last week, prompted by a change in my DNS hosting setup, I began removing it from the few personal zones I had signed. Then this Monday the .nz ccTLD experienced a
I m calling time on DNSSEC. Last week, prompted by a change in my DNS hosting setup, I began removing it from the few personal zones I had signed. Then this Monday the .nz ccTLD experienced a 